tinyCLAP: distilling constrastive language-audio pretrained models
Francesco Paissan, Elisabetta Farella
Abstract
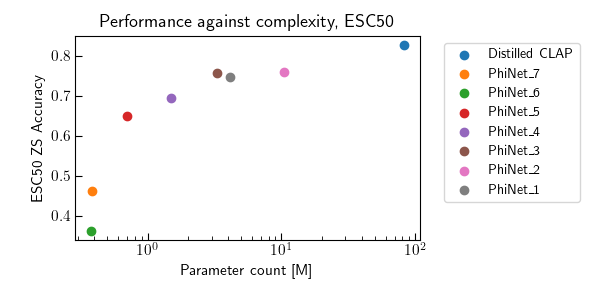
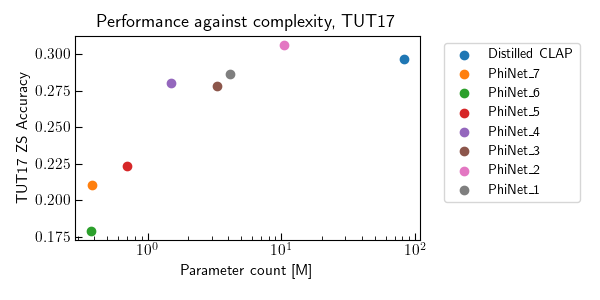
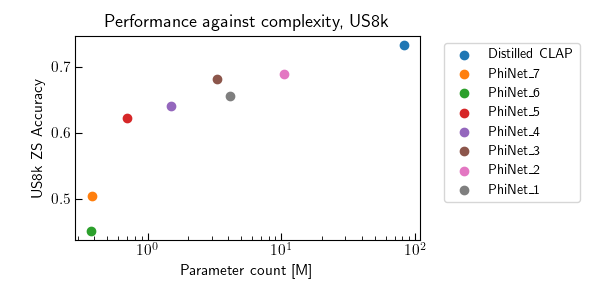
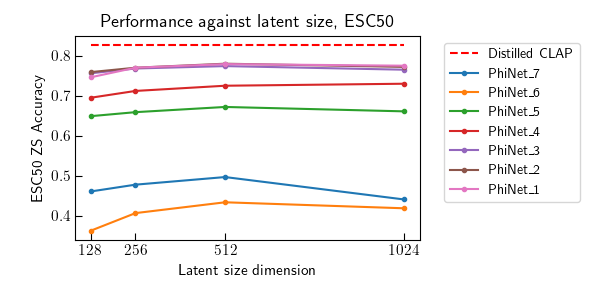
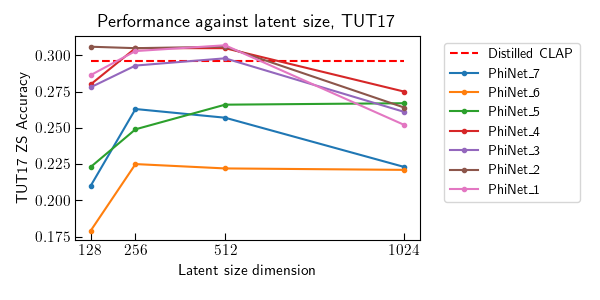
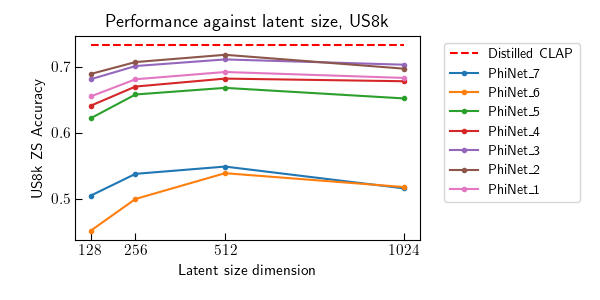
Contrastive Language-Audio Pretraining (CLAP) became of crucial importance in the field of audio and speech processing. Its employment ranges from sound event detection to text-to-audio generation. However, one of the main limitations is the considerable amount of data required in the training process and the overall computational complexity during inference. This paper investigates how we can reduce the complexity of contrastive language-audio pre-trained models, yielding an efficient model the we call tinyCLAP. We derive an unimodal distillation loss from first principles and explore how the dimensionality of the shared, multimodal latent space can be reduced via pruning. tinyCLAP uses only 6% of the original Microsoft’s CLAP parameters with a minimal reduction (less than 5%) in zero-shot classification performance across the three sound event detection datasets on which it was tested.
Contribution in a nutshell:
Play with tinyCLAP!
Upload an audio file and write a text caption. tinyCLAP will compute the similarity score and display it in the top-right box.
Citing tinyCLAP
@inproceedings{paissan24_interspeech,
title = {tinyCLAP: Distilling Constrastive Language-Audio Pretrained Models},
author = {Francesco Paissan and Elisabetta Farella},
year = {2024},
booktitle = {Interspeech 2024},
pages = {1685--1689},
doi = {10.21437/Interspeech.2024-193},
issn = {2958-1796},
}
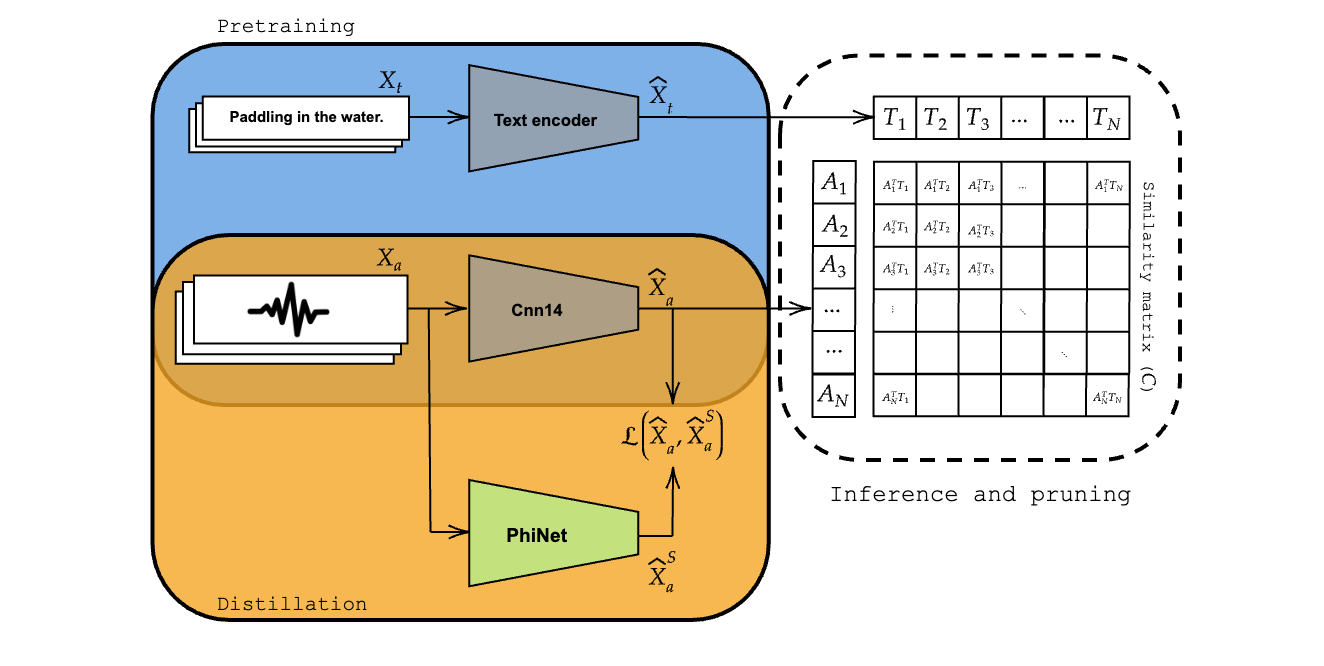
Figure 1: To distill the teacher audio encoder, we use to loss in Equation (7) of the paper. In particular, this updates the weights of the student such that the teacher and student representations are aligned, meaning they maximum cosine distance. Therefore, they will also be aligned with the original text representations. For pruning instead, we mask-out the less contributing entries of the representations in the shared multimodal latent space. This process is described in Equation (8).